
What is a Knowledge Graph? The Ultimate Guide for Engineers
If you’ve been around data engineering lately, you’ve probably heard the term “Knowledge Graph” used in the same breath as LLMs, RAG pipelines, and AI agents. Sometimes it seems like the word has been used so much that it doesn’t mean anything anymore.
Let’s fix that.
This guide won’t give you the clean, textbook definition. It will give you the working engineer’s version, which is the kind of explanation I wish someone had given me before I spent three weeks staring at a whiteboard trying to figure out why my relational schema kept breaking down.
The Problem That Knowledge Graphs Really Fix
Before we talk about what a knowledge graph is, let’s talk about the problem it solves.
Think about making a data model for a hospital. You have patients, doctors, diagnoses, medications, procedures, and insurance companies. You would set this up in a relational database as a group of tables, like a patients table, a doctors table, a diagnoses table, and so on. When you need to ask questions, you would join them together.
That works well until your question changes from “which doctor treated patient X?” to “which patients have the same diagnosis pattern, were treated by doctors who trained at the same school, and are currently taking medications that have known interactions with the new drug we’re looking at?”
At that point, your SQL query starts to look like a short story. Your joins are getting bigger. Your performance gets worse. And even more importantly, the meaning of how things are related to each other gets lost in the layers of table structure.
Knowledge graphs are made for this kind of problem, where the connections between things are just as important as the things themselves and where meaning needs to be clear, not implied.
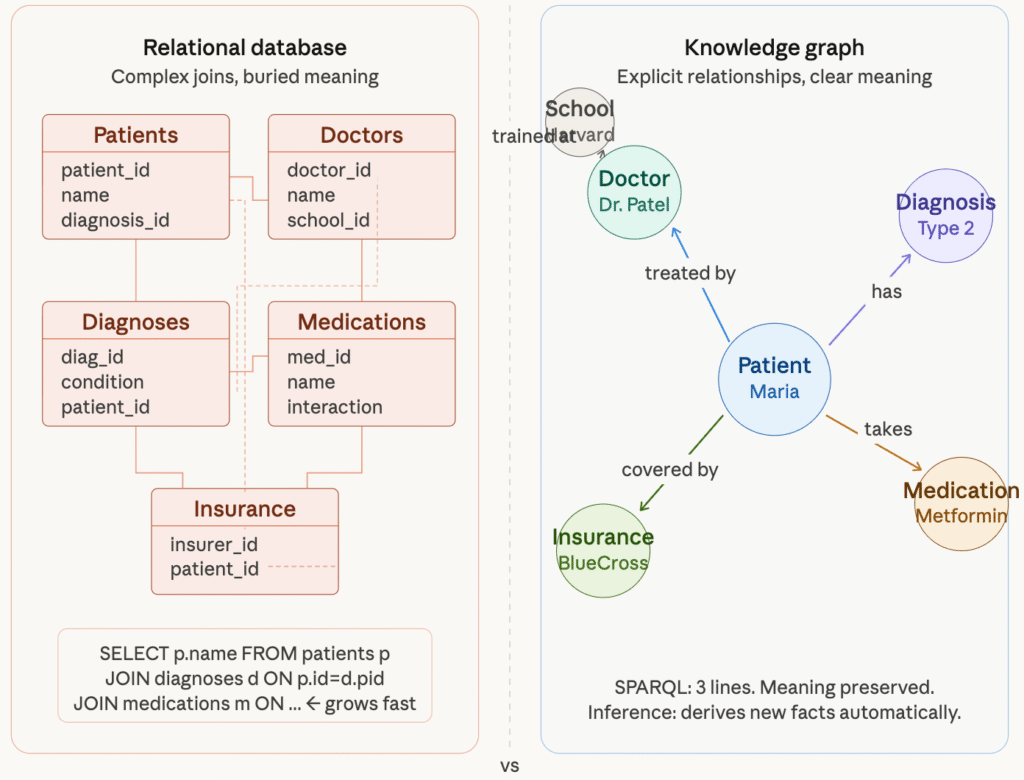
Okay, So What Actually Is a Knowledge Graph?
A knowledge graph shows information as a network of connected entities and the relationships between them. Both the entities and the relationships have meaning. Let me explain that.
A knowledge graph is made up of three main parts:
- Nodes are the things (real world entities or nouns) that make up the network, like a person, a drug, a company, or an idea.
- Edges are the connections between things (relationships or verbs), like “treats,” “manufactures,” and “belongs to.”
- Properties are things that are linked to nodes or edges, like “date of birth,” “dosage,” and “confidence score.”
That sounds a lot like any other graph database so far. The “knowledge” part is what makes a knowledge graph different. It adds a formal semantic layer that tells you what things mean, what relationships are real, and what can be logically drawn from the data. This semantic layer is usually represented as an ontology. An ontology is a structured vocabulary that describes the types of entities in your domain, the types of relationships between them, and the rules that govern both. We’ll talk about ontologies in more detail in another article, but for now, think of it as the difference between a graph that knows two nodes are connected and one that knows what that connection means.
That’s the theory. Here’s something you’ve used a hundred times that puts it into practice.
A Concrete Example: The Google Knowledge Graph
The Google Knowledge Graph is what shows you Leonardo DiCaprio’s birthdate, filmography, awards, and related actors when you search for “Leonardo DiCaprio.” Google isn’t just keeping a page about Leonardo DiCaprio. It’s holding organized information:
- Leonardo DiCaprio is a real person
- Leonardo DiCaprio was born in Los Angeles
- Leonardo DiCaprio starred in Inception
- Inception was directed by Christopher Nolan
- Christopher Nolan also directed Interstellar
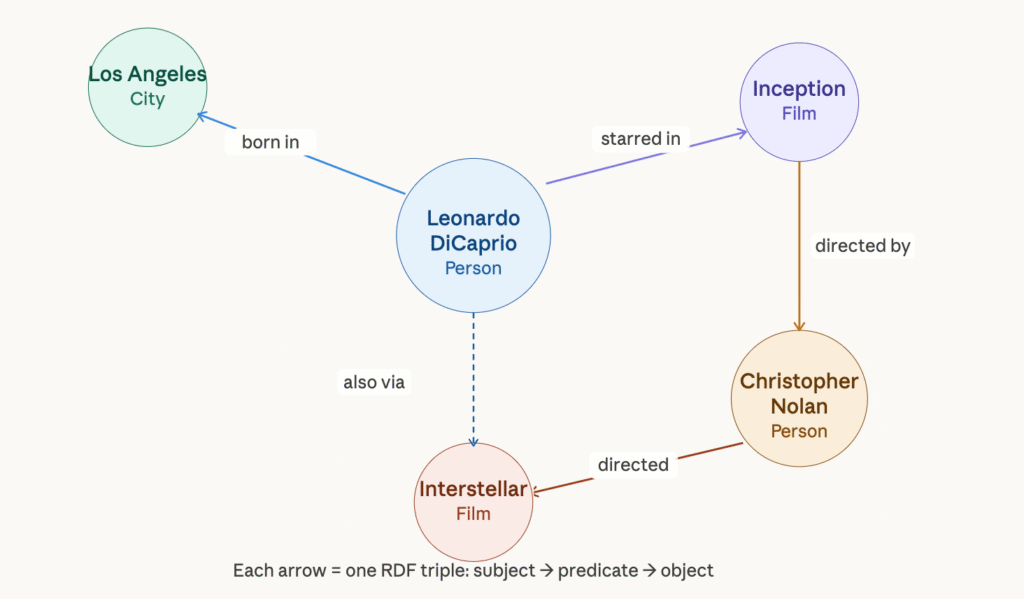
In semantic web terms, each of those facts is a relationship, or a triple, that connects entities through typed edges. And since the graph knows what kind of thing each entity is, it can answer questions that a normal search index can’t.
That’s not magic. That’s a knowledge graph working.
How Does a Knowledge Graph Store and Retrieve Information?
This is one of the most common questions from engineers encountering knowledge graphs for the first time. It’s important to answer clearly, as the storage model is different from anything in the relational world.
Storage: Triples All the Way Down
At the storage level, a knowledge graph backed by an RDF triple store keeps every fact as a triple: subject, predicate, object. The Leonardo DiCaprio example from earlier would be stored as individual triples:

Each triple is a basic, independently addressable fact. The triple store maintains several indexes over these triples, usually covering all combinations of subject, predicate, and object. This allows any query pattern to be answered efficiently, no matter which elements are specified.
Property graph databases like Neo4j take a different but related approach. They store nodes and relationships as fixed-size records with direct pointers to nearby nodes. This index-free adjacency means traversal relies on following pointers rather than looking up indexes. This is why property graphs are fast for complex traversal tasks.
Knowledge Graphs vs. Relational Databases
This is the comparison every engineer eventually needs to have, so let’s have it properly.
Relational databases are great at what they were made for: storing a lot of structured, uniform data and quickly getting it back when you know exactly what you’re looking for. A relational database is fast, reliable, and battle-tested if you need to look up order #8472 and return its line items on an e-commerce site.
The cracks start to show when:
- Your data model keeps changing. When you add a new type of relationship to a relational database, you have to change schemas, move data, and update queries. Adding a new type of relationship to a knowledge graph is as easy as adding a new triple.
- Your questions are full of relationships. In a graph, it’s easy to do multi-hop traversals like “find all entities connected to X through Y type of relationship within 3 degrees.” In SQL, it’s expensive.
- Your domain has a lot of complicated and overlapping categories. You can be a doctor, a researcher, and an author all at the same time. This gets messy quickly in a relational model. Class hierarchies and multiple inheritance make it easy to handle in a knowledge graph with a good ontology.
- You need to make inferences. This is the important part. A relational database can only provide you with what you’ve stored. A knowledge graph with a reasoning layer can derive new facts from the existing ones. If your ontology states that “every mammal is an animal” and your data mentions that “a dolphin is a mammal,” the reasoner can infer that “a dolphin is an animal” even if you haven’t stored that fact explicitly.
To be clear, this isn’t an argument that knowledge graphs are better than relational databases. They are different tools for different problems. Most real-world enterprise systems use both.
Knowledge Graphs vs. Vector Databases
This comparison is recent and relevant to what’s happening in AI right now.
Vector databases store information as high-dimensional numerical vectors, which are mathematical representations of meaning generated by embedding models. They excel at finding content with similar meanings. That’s why they’ve become the backbone of most RAG (Retrieval-Augmented Generation) pipelines.
So, why would you use a knowledge graph instead? The honest answer is: sometimes you wouldn’t. If your goal is to find the most relevant document chunks to answer a question, a vector database works well and is simpler to operate. However, vector databases have a basic limitation. They work on similarity, not meaning. They can show that two pieces of text are conceptually close, but they can’t explain why, enforce rules about what is true, or reason about relationships between specific entities.
Knowledge graphs fill that gap. They don’t replace vector databases; they complement them. The new architecture called GraphRAG, which we will explore in detail in a future article, combines both. It uses a knowledge graph for structured, rule-based reasoning about entities and relationships, and a vector database for unstructured semantic search. Together, they create AI systems that are more accurate and more explainable than either approach on its own.
If you’re building AI systems that need to be trustworthy – especially in healthcare, finance, legal, or regulated industries. This combination is essential.
Real-World Use Cases
Knowledge graphs are not just a theory; they are actively used in various industries at scale.
- Pharmaceutical and life sciences: Drug discovery pipelines use knowledge graphs to model relationships between genes, proteins, diseases, and compounds. By connecting data that used to be kept in separate silos, the identification of drug candidates has significantly sped up.
- Financial services: Fraud detection systems use knowledge graphs to find suspicious patterns among transactions, accounts, and entities. A single fraudulent actor might seem clean on their own, but their connections can expose them.
- E-commerce: Amazon’s product graph links products, categories, brands, reviews, and customer behavior. This connection supports search and recommendations on a large scale.
- Enterprise knowledge management: Large organizations use knowledge graphs to connect information across departments. This makes institutional knowledge easier to find and helps avoid the issue of “we already solved this three years ago in a different team.”
- AI assistants and agents: This is the current frontier. LLMs are good at generating believable text, but they struggle with reliably knowing specific facts about specific entities. A knowledge graph provides an AI agent with a structured, verifiable source of accurate information to reason against.
The Core Components of a Knowledge Graph Stack
If you’re planning to implement a knowledge graph, you will usually work with some combination of these components:
- A graph database or triple store: This is where your data is stored. Options include RDF triple stores like Stardog, GraphDB, and AllegroGraph, which store data as Subject-Predicate-Object triples and support SPARQL querying. There are also property graph databases like Neo4j, which uses a Node-Relationship model and the Cypher query language. We will compare these in detail in a future article.
- An ontology: This is the semantic layer that defines your domain model. It’s typically expressed in OWL (Web Ontology Language) and created using tools like Protégé or TopBraid Composer.
- An ingestion pipeline: This process transforms raw data from source systems into graph-structured data. This is often where most of the actual engineering work occurs.
- A query interface: This could be SPARQL for RDF-based systems, Cypher for Neo4j, or Gremlin for Apache TinkerPop-compatible systems.
- A reasoner: This component applies logical rules to your ontology and data to derive new facts. Common choices for OWL reasoning include HermiT and Pellet.
You don’t need all of these from the start. Many successful knowledge graph projects begin with just a graph database and a simple schema. You can add the formal ontology layer as your domain model stabilizes.
Where to Start if You’re New to This
If you’re coming to knowledge graphs from a traditional data engineering background, here’s some honest advice:
Start with the problem, not the technology. Before you choose a graph database or write an OWL axiom, take time to model your domain on a whiteboard. What are the entities? What are the relationships? Where are the current pain points in your data model?
If you have a semantic web background, try to avoid the urge to build the perfect ontology before loading any data. Get something working, then refine it.
If you are an AI/ML engineer who has heard about GraphRAG and wants to understand the knowledge graph side of it, welcome. You’re in the right place. Start with the RDF fundamentals and Neo4j basics that we will cover in upcoming articles. Once you do, the GraphRAG architecture will make much more sense.
What’s Coming Next on OntoKraft
This article offers a broad overview. The real depth is in the details, and we will cover all of them:
- Why Knowledge Graphs are the Missing Layer in Modern AI: Why LLMs alone aren’t enough and what structured knowledge adds
- RDF vs Property Graphs: A straightforward comparison with no agenda
- OWL Ontologies for Beginners: Going from zero to a working ontology
- SPARQL Tutorial: Querying knowledge graphs from scratch
- Top Knowledge Graph Tools in 2026: What’s worth your time and what isn’t
- GraphRAG Explained: The architecture that’s changing how LLMs reason
- Building a GraphRAG Pipeline from Scratch: A hands-on implementation
If you work with data for a living and haven’t yet faced a question that a relational database couldn’t handle easily, you will. When that moment comes, you’ll be glad you understood this material first.
Have questions or want to discuss something in this article? Reach out at hello@ontokraft.com - we read everything.


